Market making
I will assume the reader knows how market making in general works.
Abstract
In this project, we market make on Kalshi sports markets (and we stop when the corresponding event begins, to avoid adverse selection). Our theos are derived by aggregating sportsbooks’ odds and then quoting about them with HJB equations and engaging in dynamic behavior when necessary, i.e. when the orderbook is competitive. We employ various risk management techniques ranging from actual positional limits to redundancies in code to catch e.g. Kalshi’s webhooks going inactive.
Quoting as Monopsony
To check if we have competition, we simply quote top of book, sit back, and see if we get outbid. Conveniently, our initial quotes can be calculated as if the market is monopsonistic and then we activate competitive logic only if outbid. This baseline quoting mechanism is inspired by Avellaneda & Stoikov, 2008, using Hamilton-Jacobi-Bellman equations, as follows.
To motivate this math a little, HJB quoting is necessary in these monopsonistic markets since such markets are invariably high spread and low liquidity, with the preexisting CLOB often sitting at something absurd, e.g.
We model this demand curve via Poisson arrivals: let
With the standard parameterisation
Our value function then depends only on
Then, to mitigate inventory exposure, we skew our bid-ask quotes based on the directional exposure: if long, tighten the ask; if short, tighten the bid. The magnitude of skew depends on
There are other skewing formulae I looked at, the best of which seemed to be linear skewing:
So, we need two parameters: risk aversion
Quoting with Competition
When I started this, I had very little competition. In fact, early on, I remember once being super surprised upon discovering a competing market maker in what I had thought was my domain, and then I hit alt-tab and realized oh it was just me running two instances. But the alpha has dried up quickly and at this point we almost always have competition. They eat into the share of orderflow we absorb, which is objectively bad, but competition does make the quoting logic much easier than HJB.
The logic is best explained with a very complicated flow chart (see like a third of it in the thumbnail), but it boils down to “quote top of book unless top of book exceeds theo”. There is some sophistication regarding how we actually engage in bidding, but after a few seconds, bidding always ends as ceilings are hit and so (1) we back off, (2) our competitors back off, or (3) we all sit at a shared ceiling. Unfortunately, (3) is very common and very boring.
Execution & Infrastructure
We globally pull odds from The Odds API every 30 minutes, aggregating lines from a few dozen sportsbooks to get a no-vig implied probability. In particular, we implement a weighted average about Pinnacle (a very sharp book). We also pull odds on a per event basis when inventory skews dramatically in order to mitigate adverse selection from, say, a player being announced as injured recently (theoretically, we should lose if and only if Vegas loses, with some asterisks of course).
With these theos and the aforementioned quoting calculations, we then have WebSocket connections to Kalshi for real-time orderbook deltas and fill notifications. Orders are placed/updated in parallel via REST with connection pooling and retries. Each order has an async lock to prevent inventory runaway. On orderbook change or fill, we recalculate all four sides (checking inventory and so on) and requote.
For redundancy (and due to an Incident…), WebSocket disconnects trigger an automatic reconnect protocol with exponential backoffs. The inventory syncs from REST every 10 seconds to make sure positions don’t run away, and very primitive kill switches flood the API for a minute straight if things go particularly awry, which is unfortunately necessary since the Kalshi API tends to lie about whether an order kill succeeded…
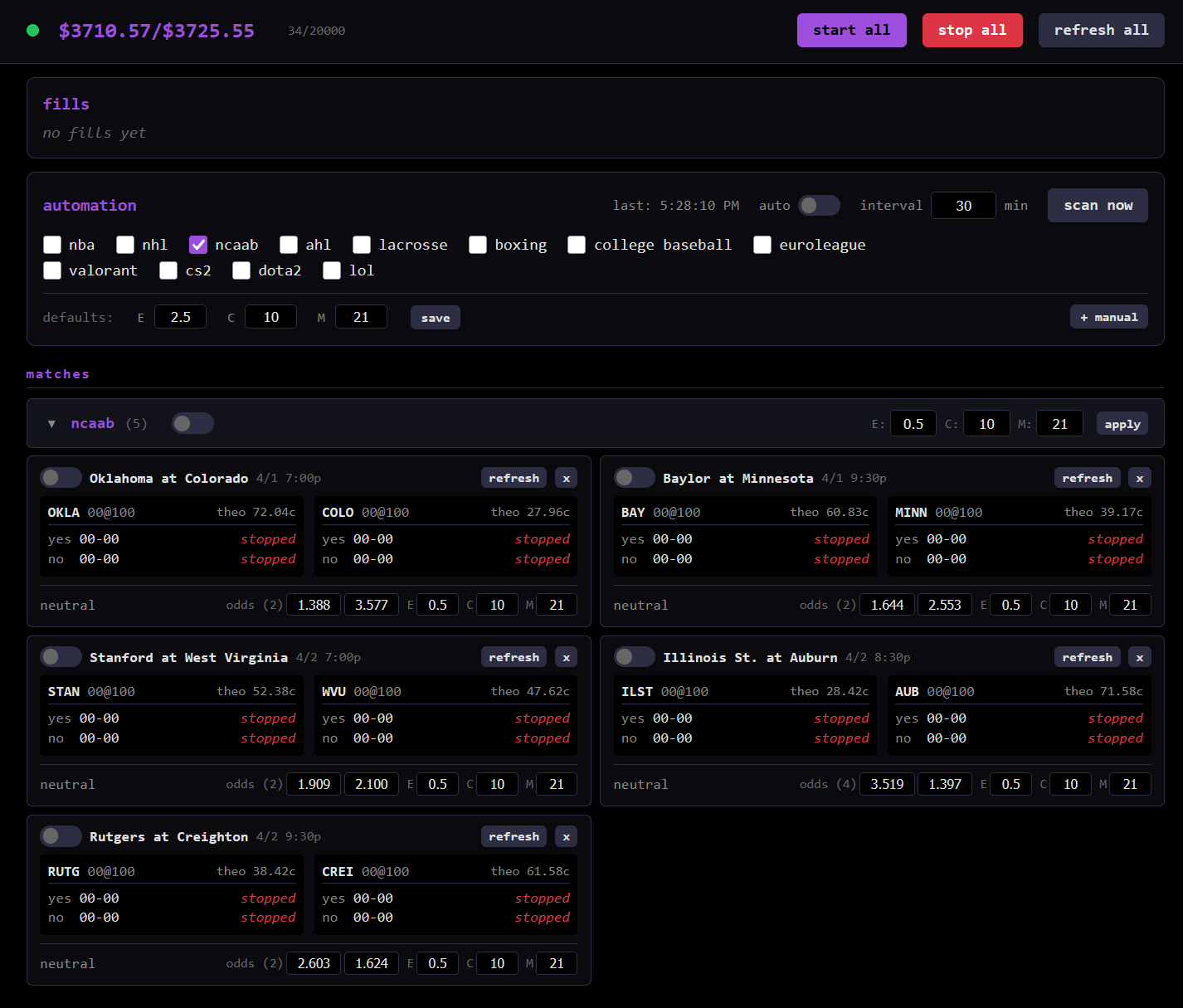
To monitor all this, we have a nice dashboard hosted locally.
Risk Management
Risk management boils down to inventory management.
We don’t care about anything else (e.g. optimising the overall portfolio) since we are not in a situation where we have limited funds and need to decide how to best allocate them; on the contrary, I don’t mind depositing more money whenever positions tie up our cash, since I want to absorb all of the orderflow.
Assuming our theo is correct, every trade is necessarily plus EV, even if we aren’t market neutral. So if we accumulate great directional exposure at a great price, I am more than happy to take the gamble. However, if our theo is outdated, we could easily be adversely selected (hence various mechanisms which activate a rechecking of the odds). Directional exposure is really scary and our main concern.
To that end, we have a hard inventory limit per match derived from (1) a constant corresponding with the sport and (2) whatever the liquidity available in that market is. Generally, I am more risk-averse for super niche sports where insider trading is a concern (esports, college baseball) and less risk-averse for more "legitimate" sports. A notable exception is boxing, an unserious sort of sport where competitors sometimes miss weight and get disqualified, some threaten to skip the fight which voids it, there's lowkey rigging which goes on, et cetera.
We track a single signed inventory which equates
We also enforce break-even ceilings when overexposed. These override the quoting logic, allowing us to take positions which are theoretically unprofitable EV-wise. For instance, if we’re overexposed to
Results
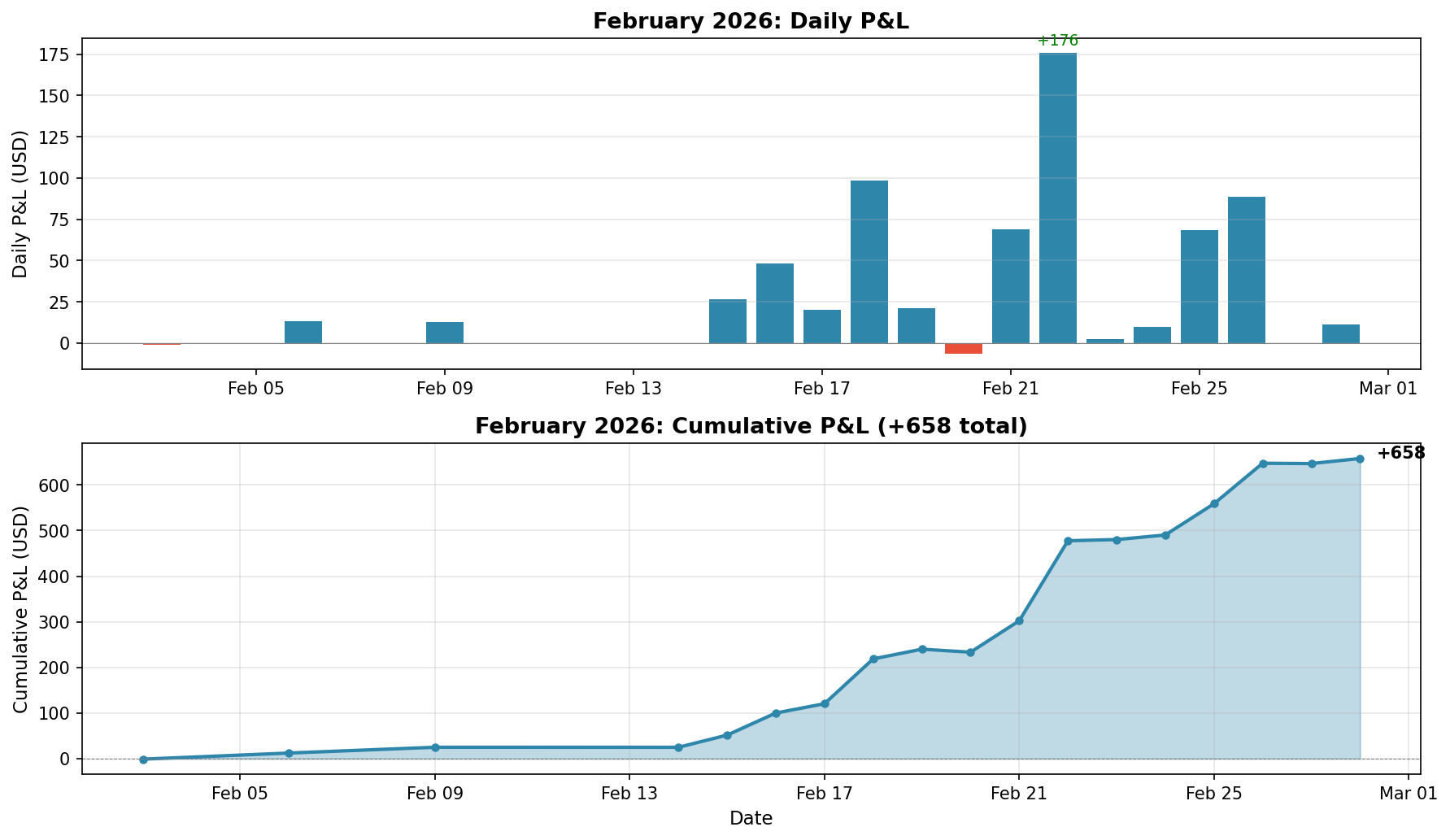
I unfortunately cannot report e.g. Sharpe; market making, particularly on prediction markets, renders these metrics pretty meaningless. Strictly binary contracts like
Thus, PnL comprises a drip of binary contracts resolving one another and then a large wave at event resolution (e.g. February 22, a Sunday, had a bunch of games resolve). There are good solutions to this issue (live calculate position value), but most of them eat up the API limit and I didn’t care enough about documentation to implement them.
In the end, I guess that this strategy is necessarily high Sharpe, high Calmar, etc., but it's also not very scalable; I generally hold all four positions top of book (
I doubt I'll do much more with this—the alpha is drying up pretty quickly. Also, as was alluded to earlier (per our